

Research Opportunities
If you are interested in performing research (MSc or PhD level) in any of the topics below, send an e-mail to Prof. Rui Pedro Paiva.
- Music Information Retrieval in general
- Music Emotion Recognition: involving Deep Learning, Machine Learning + Audio Signal Processing (for feature extraction from audio) and/or MIDI Processing (for feature extraction from MIDI) and/or Natural Language Processing (for lyrics processing), among other sources
- Automatic Music Transcription and Melody Transcription in particular
MERGE: Music Emotion Recognition - Next Generation

Description:
- Context
- Problem
- Current Research Gaps
- Objectives and Approaches
- Feature engineering/learning.To devise meaningful MER features (both handcrafted and via feature/deep learning) simultaneously in the audio and lyrics domains following a bi-modal approach.
- Robust public datasets. To collect and robustly annotate data for MER based on audio + lyrics and to release it to the MIR community.
- Static MER and MEVD. To combine these contributions to advance both static MER and MEVD, addressing bi-modal approaches and dimensional MER.
Current digital music repositories are enormous and continue to grow. More advanced, flexible and user-friendly search mechanisms adapted to individual user requirements are urgent. This has led to increased awareness in the Music Information Retrieval (MIR) area. Within MIR, Music Emotion Recognition (MER) has emerged as a significant sub-field. In fact, “music’s preeminent functions are social and psychological”, and so “the most useful retrieval indexes are those that facilitate searching in conformity with such social and psychological functions. Typically, such indexes will focus on stylistic, mood, and similarity information” (David Huron).
Google, Pandora, Spotify and Apple have MIR/MER research agendas, with existing commercial applications. However, services like the Spotify API which purport to categorise emotion have been shown not to be state of the art. To the best of our knowledge, there is no Portuguese industrial entity working on the field; however, international players may benefit from the outcomes of this research, e.g., Pandora, which endorses this proposal (attached letter). MER research promises significant social, economic, and cultural repercussions, as well as substantial scientific impact. Several open and complex research problems exist in this multidisciplinary field, touching upon audio signal processing, natural language processing, feature engineering and machine learning.
Current MER solutions, both in the audio and lyrics domains, are still unable to solve fundamental problems, such as the classification of static samples (i.e., with uniform emotion) with a single label into a few emotion classes (e.g., 4-5). This is supported by existing studies and the stagnation in the Music Information Retrieval Evaluation eXchange (MIREX) Audio Mood Classification (AMC) task (music-ir.org/mirex/), where accuracy stabilized at ~69%. Nevertheless, more complex problems have been addressed, e.g., music emotion variation detection (MEVD), with even lower reported results (~20%).
We believe that, at the current stage of MER, rather than tackling complex problems, effort should be refocused on simpler static single-label classification, with a low number of classes, and exploiting the combination of audio and lyrics via a bi-modal approach.
There exists a significant corpus of research on MER, ranging from fundamental problems of static single-label classification to higher-level work on multi-label classification or MEVD. However, current results are low and limited by a “glass ceiling”. In previous work, we demonstrated this to be partly due to two core problems: i) lack of emotionally-relevant features; ii) absence of public, sizeable and quality datasets. We created public robust (although somewhat small) MER datasets and emotionally-relevant audio and lyrics features (e.g., music expressivity and text stylistic features, such as vibrato or slang). This strategy was successful and led to ~10% increase in classification performance,
and, thus, should be further pursued. The lack of robust and sizeable datasets impacts deep learning (DL) research on MER as well. While DL is widespread in MIR, MER datasets are not sufficiently large or well-annotated to train fully end-to-end models.
We seek to advance MER research by following an explicitly bi-modal approach which models lyrics and audio simultaneously, and define the following scientific objectives:
As a technological objective, we will develop two MER software applications (a standalone and a web app) to demonstrate our scientific innovations.
Keywords:
Music Emotion Recognition, Music Information Retrieval, Feature Engineering, Audio Signal Processing, Natural Language Processing, Machine Learning, Deep Learning
Dates:
Start date: January 1, 2022
End Date: December 31, 2024
Team (alphabetical order):
Alice Mangara (MSc student)
Diogo Rente (BSc student)
Gabriel Saraiva (MSc Student)
Guilherme Almeida (MSc student)
Guilherme Branco (BSc Student)
Hugo Redinho (MSc Student)
Luís Carneiro (MSc Student)
Luís Seco (MSc student)
Mariana Paulino (MSc student)
Matthew Davies (Senior Researcher)
Pedro Louro (PhD Student)
Pedro Sá (MSc Student)
Rafael Matos (MSc Student)
Renato Panda (Professor)
Ricardo Santos (PhD Student)
Ricardo Malheiro (Professor)
Rui Pedro Paiva (Professor, Project Coordinator)
Samuel Machado (MSc student)
Tiago Ribeiro (PhD student)
Funded by:
FCT - Fundação para a Ciência e Tecnologia, Portugal (PTDC/CCI-COM/3171/2021)
Budget:
€ 195 892
Resources:
Results and conclusions:
MOODetector: A System for Mood-based Classification and Retrieval of Audio Music
Description:
“Music’s preeminent functions are social and psychological”, and so “the most useful retrieval indexes are those that facilitate searching in conformity with such social and psychological functions. Typically, such indexes will focus on stylistic, mood, and similarity information” (David Huron, 2000). This is supported by studies on music information behaviour that have identified music mood as an important criterion for music retrieval and organization.
Besides the music industry, the range of applications of emotion detection in music is wide and varied, e.g., game development, cinema, advertising or the clinical area (in the motivation to compliance to sport activities prescribed by physicians, as well as stress management).
Compared to music emotion synthesis, few works have been devoted to emotion analysis. From these, most of them deal with MIDI or symbolic representations. Only a few works tackle the problem of emotion detection in audio music signals, the first one we are aware of published in 2003. Being a very recent research topic, many limitations can be found and several problems are still open. In fact, the present accuracy of those systems shows there is plenty of room for improvement. In a recent comparison, the best algorithm achieved 65% classification accuracy in a task comprising 5 categories (MIREX 2010). The effectiveness of such systems demands research on feature extraction, selection and evaluation, extraction of knowledge from computational models and the tracking of emotion variations throughout a song. These are the main goals of this project.
Keywords:
Music Emotion Recognition, Music Information Retrieval, Feature Engineering, Audio Signal Processing, Natural Language Processing, Machine Learning
Dates:
Start date: May 16, 2010
End Date: November 14, 2013 (formal date, although research work has continued)
Team (alphabetical order):
Álvaro Mateus (BSc student)
Amílcar Cardoso (Professor)
António Pedro Oliveira (PhD student)
João Francisco Almeida (BSc student)
João Miguel Paúl (MSc student)
João Fernandes (MSc student)
Luís Cardoso (MSc student)
Renato Panda (PhD student)
Ricardo Malheiro (PhD student)
Rui Pedro Paiva (Professor, Project Coordinator)
Funded by:
FCT (Fundação para a Ciência e Tecnologia, Portugal)
Budget:
77304 €
Resources:
Results and conclusions:
Mellodee – Melody Detection in Polyphonic Audio
Description:
In this project, we address the problem of melody detection in polyphonic audio. The resulting system comprises three main modules, where a number of rule based procedures are proposed to attain the specific goals of each unit:
- Pitch detection;
- Determination of musical notes (with precise temporal boundaries and pitches);
- Identification of melodic notes. We follow a multi stage approach, inspired on principles from perceptual theory and musical practice. Physiological models and perceptual cues of sound organization are incorporated into our method, mimicking the behavior of the human auditory system to some extent. Moreover, musicological principles are applied, in order to support the identification of the musical notes that convey the main melodic line.
Keywords:
Melody detection in polyphonic audio, music information retrieval, melody perception, musicology, pitch detection, conversion of pitch sequences into musical notes, pitch tracking and temporal segmentation, onset detection, identification of melodic notes, melody smoothing, note clustering.
Dates:
Start date: September 1, 2002
End Date: September 1, 2006
Team (alphabetical order):
Funded by:
CISUC
Budget:
Financial support to the participation in MIR conferences.
Resources:
Results and conclusions:
In order to assess the generality of our approach, we evaluated it with the test set used in the ISMIR’2004 Audio Description Contest (ADC), which consisted of 10 samples (around 20-30 seconds each). The results achieved for the defined pitch contour metrics were, respectively, 75.1% (considering only the matching over melodic notes) and 71.1% (considering the capability of the algorithm to exclude non-melodic notes).
In summary, our algorithm performed best in this evaluation. In the ADC, the average between the training and testing sets were computed, leading to 69.1% accuracy (excluding melodic notes). These are not the results reported in the ADC’s site due an alignment problem in the algorithm later reported by the organizers.
The algorithm was also tested using the Music Information Retrieval Evaluation eXchange’2005 (MIREX 2005). There, results were not as good: : 62.7% for melodic notes and 57.8% (evaluating the capability to remove non-melodic. Notes). In any case, our algorithm ranked 3rd in this evaluation.
In brief, experimental results show that our method performs satisfactorily in the employed test sets, which encompass inherent assumptions. However, additional difficulties are encountered in song excerpts where the intensity of the melody in comparison to the surrounding accompaniment is not so favorable.
To conclude, despite its broad range of applicability, most of the research problems involved in melody detection are complex and still open. Most likely, sufficiently robust, general, accurate and efficient algorithms will only become available after several years of intensive research.
Details:
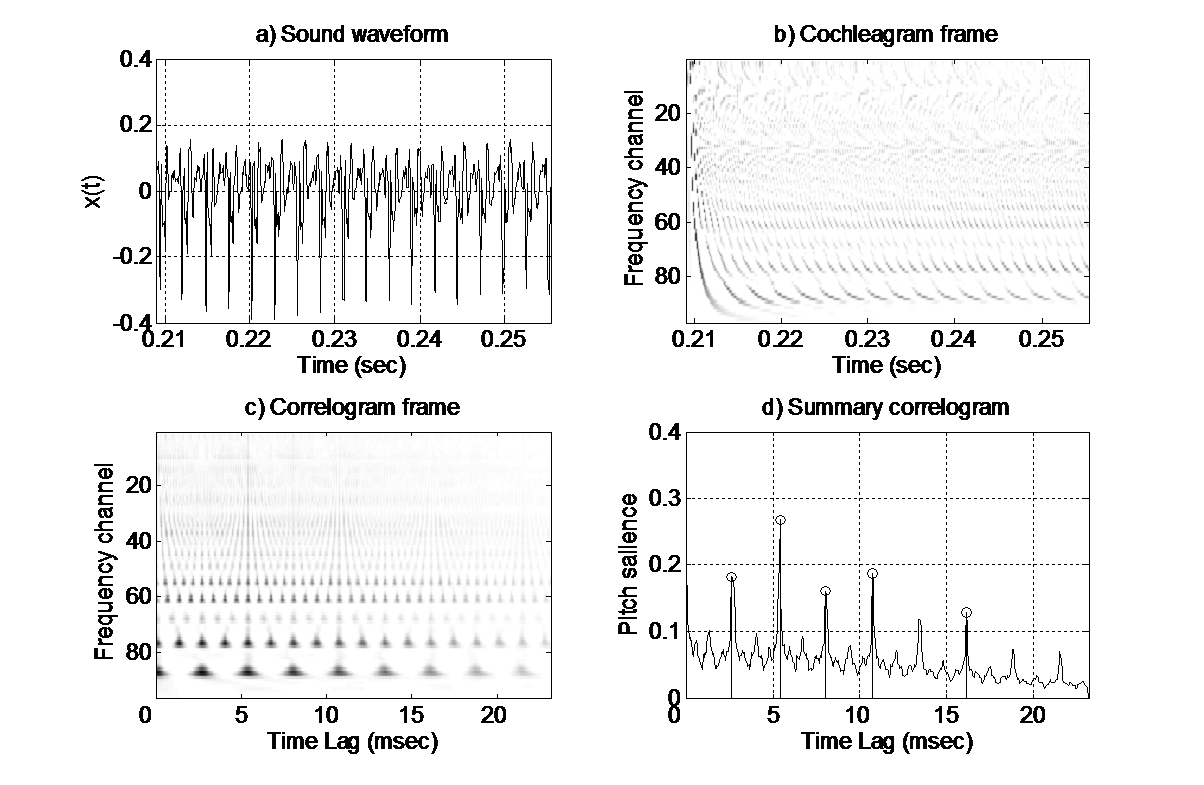
Pitch Detection:
Our algorithm starts with an auditory model based pitch detector, where multiple pitches are extracted in each analysis frame. These correspond to a few of the most intense fundamental frequencies, since one of our basis assumptions is that the main melody is usually salient in musical ensembles.
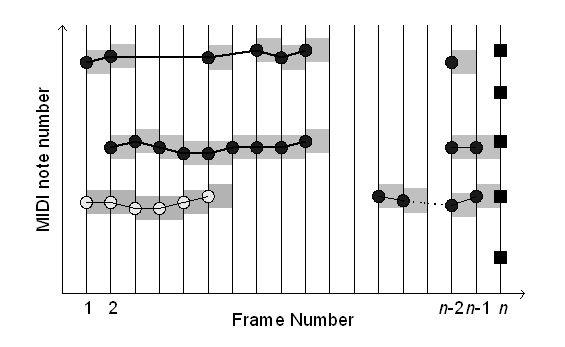
Determination of musical notes:
Unlike most other melody extraction approaches, we aim to explicitly distinguish individual musical notes, characterized by specific temporal boundaries and MIDI note numbers. In addition, we store their exact frequency sequences and intensity related values, which might be necessary for the study of performance dynamics, timbre, etc. We start this task with the construction of pitch trajectories that are formed by connecting pitch candidates with similar frequency values in consecutive frames. The objective is to find regions of stable pitches, which indicate the presence of musical notes.
Since the created tracks may contain more than one note, temporal segmentation must be carried out. This is accomplished in two steps, making use of the pitch and intensity contours of each track, i.e., frequency and salience based segmentation. In frequency based track segmentation, the goal is to separate all notes of different pitches that are included in the same trajectory, coping with glissando, legato and vibrato and other sorts of frequency modulation. As for salience based segmentation, the objective is to separate consecutive notes at the same pitch, which may have been incorrectly interpreted as forming one single note.
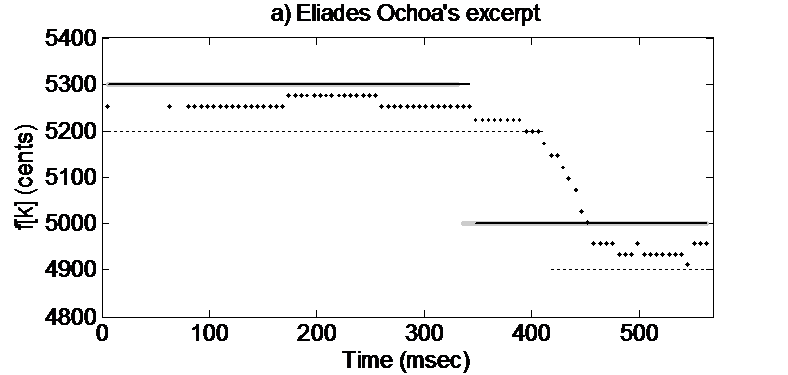
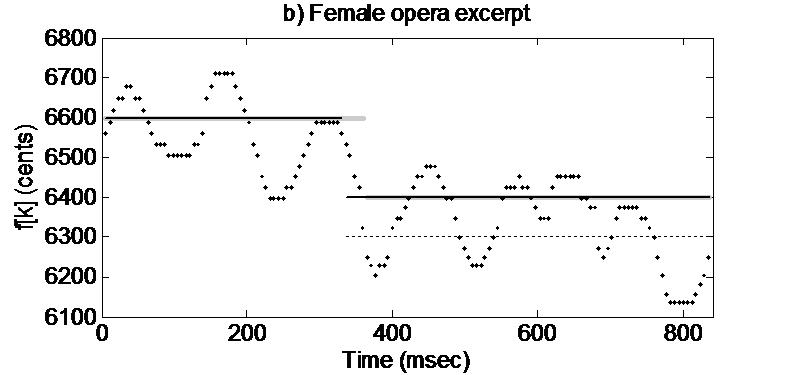
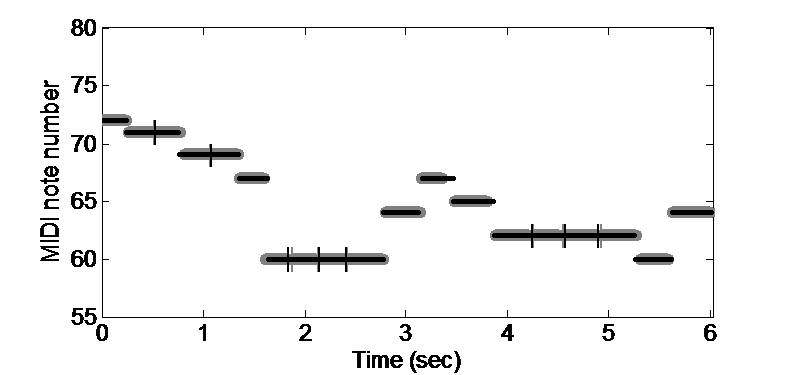
Identification of melodic notes:
Regarding the identification of the notes bearing the melody, we found our strategy on two core assumptions that we designate as the salience principle and the melodic smoothness principle. By the salience principle, we assume that the melodic notes have, in general, a higher intensity in the mixture (although this is not always the case). As for the melodic smoothness principle, we exploit the fact that melodic intervals tend normally to be small. Finally, we aim to eliminate false positives, i.e., erroneous notes present in the obtained melody. This is carried out by removing the notes that correspond to abrupt salience or duration reductions and by implementing note clustering to further discriminate the melody from the accompaniment.